This is a great development for KV cache compression. I did notice a missing citation in the related works regarding the core mathematical mechanism, though. The foundational technique of applying a geometric rotation prior to extreme quantization, specifically for managing the high-dimensional geometry and enabling proper bias correction, was introduced in our NeurIPS 2021 paper, "DRIVE" (https://proceedings.neurips.cc/paper/2021/hash/0397758f8990c...). We used this exact rotational approach and a similar bias correction mechanism to achieve optimal distributed mean estimation. I also presented this work and subsequent papers in a private invited talk at Google shortly after publication. Given the strong theoretical overlap with the mechanisms in TurboQuant and PolarQuant, I hope to see this prior art acknowledged in the upcoming camera-ready versions.
gavinraylast Wednesday at 1:33 PM
Can someone ELI5 these two concepts please, which make no sense to me:
> "TurboQuant starts by randomly rotating the data vectors. This clever step simplifies the data's geometry"
I don't understand how taking a series of data and applying a random rotation could mathemetically lead every time to "simpler" geometry.
If I throw a bunch of shapes on the ground, tightly packed and touching each other, then rotate all of them, you can't guarantee that the new conglomerate shape is any more/less "simple" than before, right?
> "Johnson-Lindenstrauss Transform to shrink complex, high-dimensional data while preserving the essential distances and relationships between data points. It reduces each resulting vector number to a single sign bit (+1 or -1)."
How can a boolean value preserve all of the relational and positional information between data points?
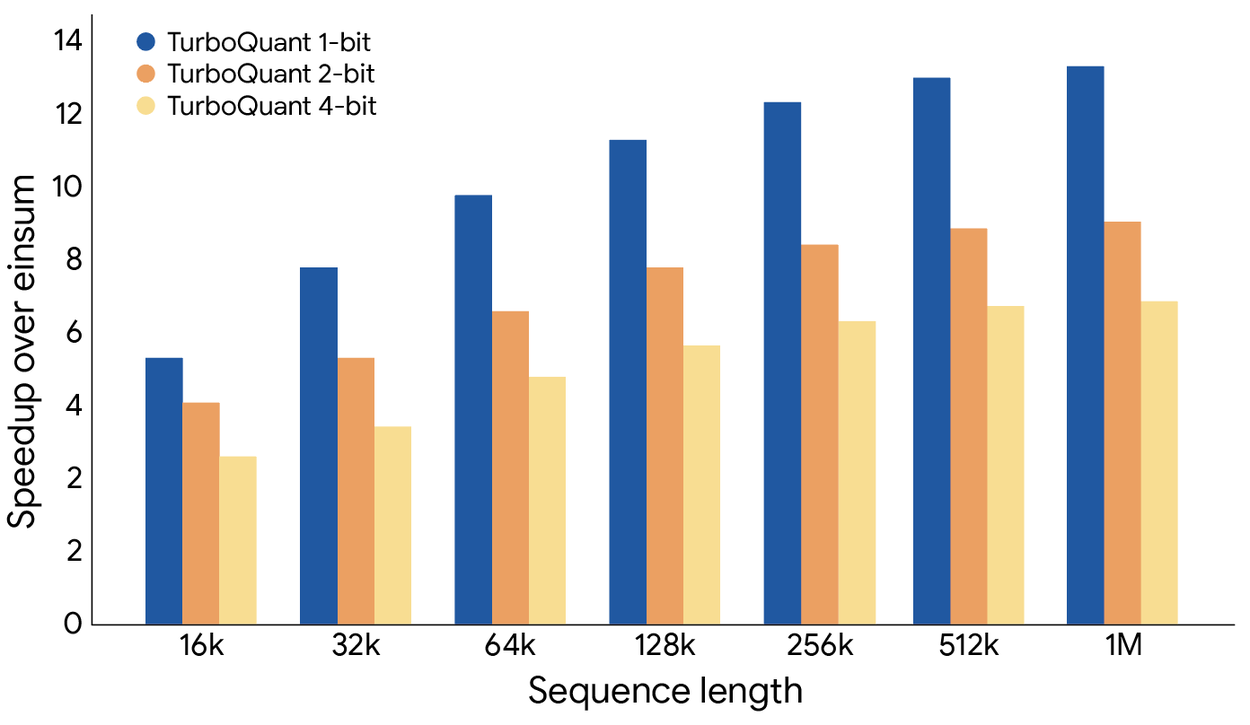
The speedup labels on the vertical axis are 0, 2, 2, 4, 6, 8... Why is 2 repeated? Did they just have nano-banana make them some charts? Can they not be bothered to use matplotlib or bokeh and directly render a graph? I don't know, maybe there is some legitimate reason that I don't know about for making a single value occur multiple times on a graph axes, but if that is the case, then they probably need to explain it in the figure caption. So it's either a "GenAI special" or it's poor communication about how to read the graph...
Do you have literally any clue what Polar Quantization is? Would this make me think, "I kind of have a high level understanding of that, let me go get the details from the paper."
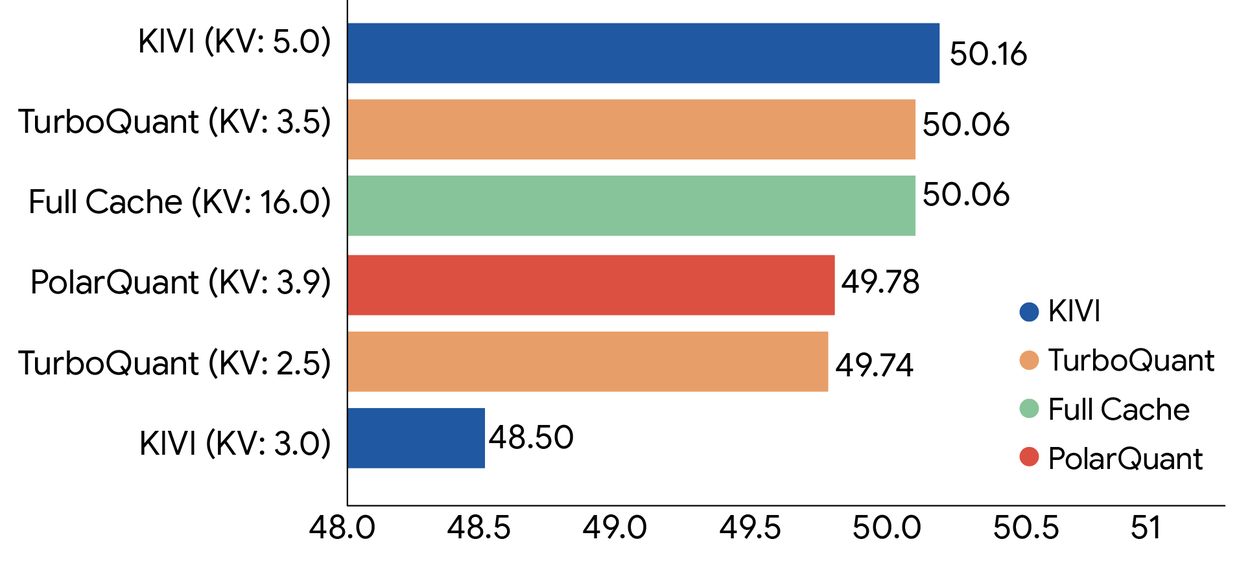
The left hand side of the graph, which is normally assumed to start at 0, starts at 48. Those MASSIVE differences you see in the figure? Only a few percent. And that's a deception but only if the figure is even accurate, because we saw earlier they can't even get figure axes correct.
benoblast Wednesday at 7:02 AM
This is the worst lay-people explanation of an AI component I have seen in a long time. It doesn't even seem AI generated.
pstolllast Wednesday at 11:48 AM
And a group has published an independent working implementation today, nice to see:
Here's my attempt at a undergrad-level summary (corrections welcome!):
The core idea is to quantize KV cache, but do so in a way that destroys minimal information. In this case, it's similarly scores between vectors. The simplest way to do this is to change all the elements from 16bit of precision to, say, 4 bits (Scalar Quant.). These papers improve on it by realizing: almost all the energy (concentration of measure) is towards the equator of the hypersphere (normally distributed as 1/d; d=vector dimensionality). (The curse/blessing of hyper dimensionality strikes again.) So when we quantize the elements (think "latitudes", e.g. to the nearest degree) we destroy a lot of information because basically all the vectors were around the equator (so some latitudes have a lot of vectors and some have very few). The idea is to rotate the vectors away from the equator so they're more consistently distributed (to better preserve the entropy during quantization, which I guess was amitport's DRIVE idea). PolarQuant does a hyperpolar coordinate transform which superficially seems neat for preserving entropy because of this equator/polar framing (and ultimately unnecessary as shown by TurboQuant). They also realized there's a bias to the resulting vectors during similarity, so they wrote the QJL paper to fix the bias. And then the TurboQuant paper took PolarQuant + QJL, removed the hyperpolar coords, and added in some gross / highly-pragmatic extra bits for important channels (c.f. elements of the vectors) which is sort of a pathology of LLMs these days but it is what it is. Et voila, highly compressed KV Cache. If you're curious why you can randomly rotate the input, it's because all the vectors are rotated the same, so similarity works out. You could always un-rotate to get the original, but there's no need because the similarity on rotated/unrotated is the same if you compare apples to apples (with the QJL debiasing). Why was PolarQuant even published? Insu Han is solely on that paper and demanded/deserved credit/promotion, would be my guess. The blog post is chock-full of errors and confusions.
The blog is new but the paper was submitted almost one year ago: https://arxiv.org/abs/2504.19874. Anyone has ideas if this is already implemented in many models (at least Gemini, I guess)? If that's the case, can I expect cheaper RAM for my computer :D
Serhii-Setlast Wednesday at 3:02 PM
Compression research keeps producing surprisingly practical results. The interesting parallel in image formats — AVIF and JPEG XL both came from video codec research (AV1 and JPEG committee respectively), and the compression gains translated almost directly. Makes me wonder how much of the current AI quantization work will eventually land in production inference the same way.
zeeshana07xlast Wednesday at 9:46 AM
The gap between how this is described in the paper vs the blog post is pretty wide. Would be nice to see more accessible writing from research teams — not everyone reading is a ML engineer
bluequbitlast Wednesday at 6:42 AM
I did not understand what polarQuant is.
Is is something like pattern based compression where the algorithm finds repeating patterns and creates an index of those common symbols or numbers?
bilsbielast Wednesday at 12:37 PM
It seems like most breakthroughs I see are for efficiency? What are the most importsnt breakthroughs from the past two or three years for intelligence?
htrplast Wednesday at 10:13 PM
The actual paper from April 2025
TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
It could turn a 1M context system to a 4M context system. TurboQuant-style KV-cache compression makes longer context windows cheaper to serve. Not exactly sure how much increase in context size though.
ssijaklast Wednesday at 11:32 AM
For my grug brain can somebody translate this to ELIgrug terms?
Does this mean I would be able to run 500b model on my 48gb macbook without loosing quality?
maurelius2last Wednesday at 7:46 AM
I'm somewhat at a loss here other than understanding the fundamentals. Can someone tell me how the compression impact performance?
iddanlast Wednesday at 1:19 PM
I am guessing as Google is vertically integrated and "actually pays" for AI infra (compared to OpenAI & Anthropic that receives hardware as partnerships) they have a more urgent incentive to reduce model sizes. Also, Google and Apple will be the first to gain from running model on-device
mmastraclast Wednesday at 1:44 PM
Is this a tradeoff between GPU-computation-expense vs accuracy? ie: you could quantize into segments or grids on the unit circle/sphere/etc, but that's too expensive so it's better to just quantize to a Cartesian grid because the GPU can decompress cheaper?
macleginnlast Wednesday at 11:14 AM
"TurboQuant proved it can quantize the key-value cache to just 3 bits without requiring training or fine-tuning and causing any compromise in model accuracy" -- what do each 3 bits correspond to? Hardly individual keys or values, since it would limit each of them to 8 different vectors.
lwhilast Wednesday at 12:42 PM
Will this help us run models locally?
antiresonantyesterday at 5:31 PM
At this rate, the current AI era is going to clear the queue of all mathematics that's ever been created but not yet applied.
moktonarlast Wednesday at 7:32 AM
Aren’t polar coordinates still n-1 + 1 for radius for n-dim vector? If so I understand that angles can be quantized better but when radius r is big the error is large for highly quantized angles right? What am I missing?
lucrbvilast Wednesday at 8:50 AM
Sounds like Multi-Head Latent Attention (MLA) from DeepSeek
_s_a_m_last Wednesday at 1:11 PM
has the word "advanced", gotta be good
naaskinglast Wednesday at 1:47 PM
This sounds great! TurboQuant does KV cache compression using quantization via rotations, and ParoQuant [1] does weight compression using quantization via rotations! So we can get 4-bit weights that match bf16 precision, the KV cache goes down to 3 bits per key. This brings larger models and long contexts into the range of "possibly runnable" on beefy consumer hardware.
Pied Piper vibes. As far as I can tell, this algorithm is hardly compatible with modern GPU architectures. My guess is that’s why the paper reports accuracy-vs-space, but conveniently avoids reporting inference wall-clock time. The baseline numbers also look seriously underreported. “several orders of magnitude” speedups for vector search? Really? anyone has actually reproduced these results?
{kind=link}
{kind=link}