For those who would like to know the total and active parameter count of this model: even though Google doesn't disclose the model technicals, we can infer them within relatively tight margins based on what we do know.
We know they serve the model on TPU 8i, which we have plenty of hard specs for (so we know the key constraints: total memory and bandwidth and compute flops). We can also set a ceiling on the compute complexity and memory demand of the model based on knowing they will be at least as efficient as what is disclosed in the Deepseek V4 Technical Report.
We can also assume that the model was explicitly built to run efficiently in a RadixAttention style batched serving scenario on a single TPU 8i (so no tensor parallelism, etc. to avoid unnecessary overheads... Google explicitly designed the 8th-generation inference architecture to eliminate the need for tensor sharding on mid-sized models).
We know Google intends to serve this model at a floor speed of around 280 tok/s too.
Putting all these pieces together, we can confidently say this model is ~250-300B total, and 10-16B active parameters. Likely mostly FP4 with FP8 where it matters most.
I do model serving optimization work. This is napkin math.
Edit: There's one factor I under-rated in my initial estimate... TurboQuant. This is a compute to KV memory use tradeoff. It's plausible with TurboQuant at a quality-neutral setting they've gotten the model up to 400B with similar economics. This is a variable effecting concurrency and the the way they decided total model size was likely based on what they see for the average user's average KV cache depth in real-world usage.
Interesting pricing direction. I don't think we have ever seen a 3x price increase for in the immediate next same-sized model (and lol @ 3 only ever getting a preview).
3.5 flash costs similar to Gemini 2.5 pro which was $1.25/$10
SXXyesterday at 6:18 PM
> Create animated SVG of a frog on a boat rowing through jungle river. Single page self contained HTML page with SVG
I have google ai pro plan and tried antigravity with 3.5 flash but it used up all my quota in two prompts. If that is not a bug then it is seriously unusable.
gertlabstoday at 2:32 AM
Taking into account that this is a flash model, it's a strong release. It's very fast and frontier-ish for the price.
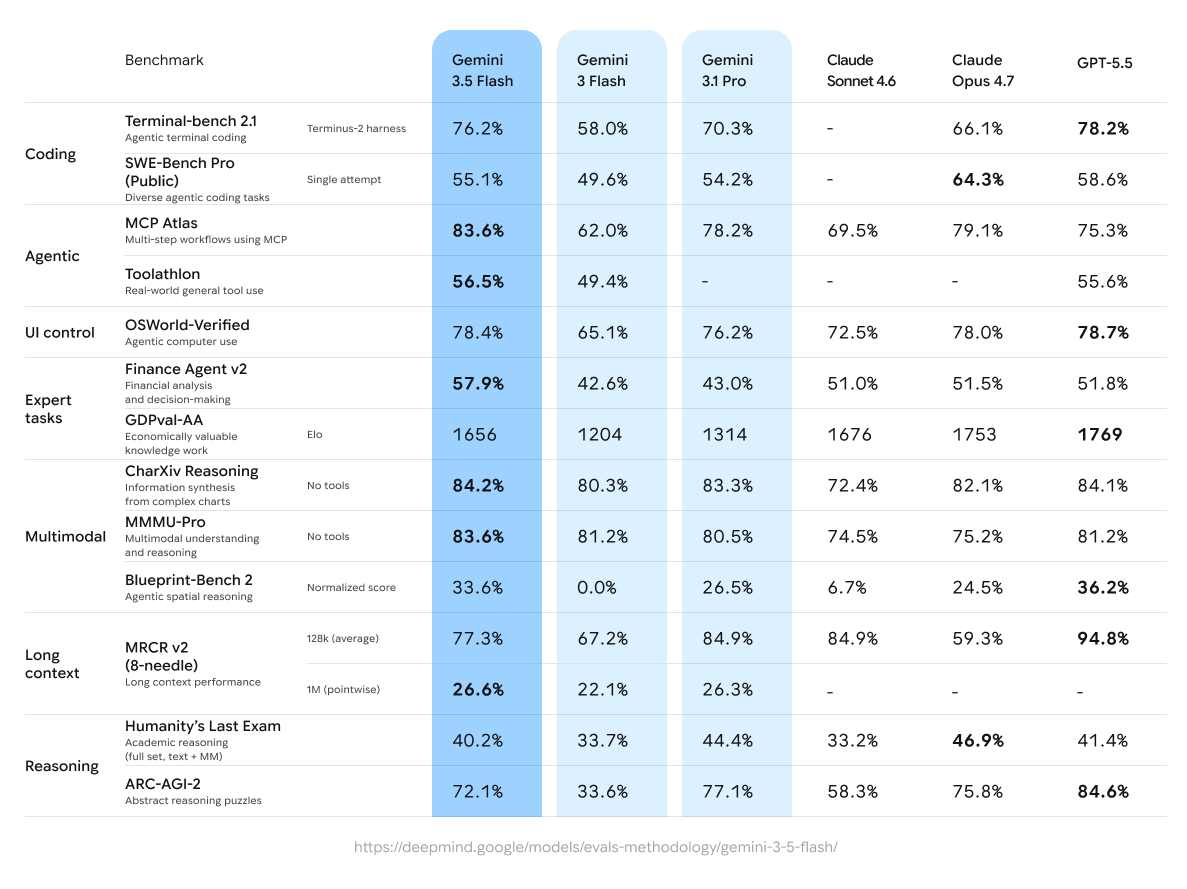
Raw intelligence is high for a flash model. But Google's problem has always been productization and tool use, whereas raw intelligence is always competitive. It does not look like they solved that with this release -- in fact, their tool use delta (the improvement in scores when given arbitrary tools and a harness) has actually regressed from some previous models.
(Switch to the cost vs performance chart to see how far this is off the Pareto frontier)
margorczynskiyesterday at 10:13 PM
Wow at the price hike. Still I think in the long run the Chinese will win if they're able to produce hardware comparable to Nvidia.
npnyesterday at 6:57 PM
The price is crazy.
And I guess Gemini 3.5 pro will have the pricing increment, too. 12 x 5 = 60?
It seems like google does want us to use Chinese models.
wg0yesterday at 7:59 PM
3x price increase for a similar model almost. And they said AI would be cheaper and ubiquitous.
s3pyesterday at 6:43 PM
Yikes. I think the concept of a 'flash' model is changing, no? Google used to market this as its lower-intelligence, faster, cheaper option. I appreciate that they are delivering on both of those, but personally I would appreciate if they could create an incremental knowledge improvement while holding price steady. Fortune 500 companies have to make their money I guess.
OsrsNeedsf2Pyesterday at 6:38 PM
Beats 3.1 Pro for price per token, but artificial analysis is showing it's dumber per token and costs more overall
asaryesterday at 6:04 PM
$1.5/m input tokens
$9/m output tokens
6x the price of 3.1 flash lite
AgentMasterRacetoday at 3:33 AM
Gemini 3.1 probation is literally the worst AI when I cycle from opus to got 5.5 then finally Gemini. It's actually insane that it's a frontier model. I rage at it more than my wife.
brikymyesterday at 9:25 PM
How is this progress? The token cost just keeps going up and up. Flash is the new Pro? Do the models actually cost more to run or is it fattening margins?
nikhilpareek13yesterday at 9:14 PM
worth noting that Google marked this stable rather than preview, which is unusual compared to their recent releases. Pair that with the 3x price hike and flash pricing now reads like long-term floor they want, not a temporary thing they will walk back later. But its hard to tell yet whether that's Google specifically reading the room or the whole industry quietly resetting the cheap-inference baseline.
himata4113yesterday at 6:05 PM
Engineers at google have publically stated that the models are too big and are far from their potencial. Glad they're being proven right with every release.
They continue to focus on smaller models while openai and anthropic are increasing compute requirements for their SOTA models.
staredyesterday at 9:37 PM
China: we don’t need to use US models, we can distill them ourself
Google: we don’t need Chinese to distill our models, we can do it ourself
paol_tajayesterday at 11:58 PM
That pelican looks like it just sold a SaaS company and bought a bike because its therapist said it needed balance.
but latency in real GUI workflows with 50+ steps is still the elephant in the room for cloud-based agents
razodactyltoday at 1:21 AM
Aw. The listen to article widget doesn't work properly on mobile Safari and when using the options button, the popup appears below the "In this article" dropdown occluding it.
At least it read the authors of the article to me.
I wish we would push more towards testing code. Agentic AI excel when it's engaged.
Alifatiskyesterday at 8:51 PM
The demo of the model in Antigravity automatically rename and categorize unstructured assets using vision was quite cool, it demodulates that the IDE sidepanel can be used for more than just coding. I wonder if the harness in Antigravity is based on Gemini cli or if they are completely different. Could Gemini cli do the same task? Or is the vision feature a Antigravity thing?
sbinneeyesterday at 10:13 PM
While I am excited, the price compared to gemini 3 flash preview which I used for the longest time is x3 more. Upon arrival of deepseek v4 flash, I am a happy user of deepseek. We will see how long that reign would last after I try this new gemini.
golferyesterday at 7:04 PM
Arena.ai:
> Gemini 3.5 Flash’s pricing shifts the Pareto frontier in Text. 8 models from
GoogleDeepMind dominate the Text Arena Pareto curve where only 4 labs are represented for top performance in their price tiers.
It’s not possible to uptrain on preview releases and it did not get that much love for a while.
sigbetatoday at 2:22 AM
I am interested to see how they will serve demand with they TPU monopoly have.
aliljetyesterday at 6:20 PM
Is there a good benchmark tracking hallucinations? The models are all incredibly good now, even the open ones, and my hope is that the rate of hallucinations is something that's falling off in concert with larger and larger context lengths.
mchusmatoday at 1:29 AM
I have thought about this and I think overall, this was a disappointing release from Google. I'm not sure the sentiment, but this feels like a miss.
What they did do in the keynote was spend a lot of time talking about their distribution advantage, and how they can own the consumer in search. But not a lot that will benefit partners or developers.
Basically, they released something broadly competitive with Sonnet 4.6, a new Omni model that seems interesting but unclear yet. They have completely ceded the frontier to OpenAI / Anthropic, and are saying "look for pro next month".
The best release since nano banana pro from Google has been Gemma.
jonnyasmaryesterday at 11:29 PM
The $1.50/$9.00 pricing is a meaningful shift if you've been running Gemini as the "fast iteration" half of a multi-model coding workflow. I've had Claude Code, Codex, and Gemini CLI running side by side and the working split was "Gemini for quick scaffolding and exploration where the cost of being wrong is low, Sonnet for correctness-critical stuff." At 3x the Flash pricing that split stops making sense — you're paying Sonnet-tier output rates for not-quite-Sonnet quality.
For pure chat that's annoying but tolerable. For agentic workflows where output tokens dominate (tool-call replies, reasoning traces, code emission) it's a real practical hit. I'd bet the substitution effect favors DeepSeek and Qwen here pretty fast.
eisyesterday at 6:26 PM
3.5 Flash was more expensive than 3.1 Pro to run the Artifical Analysis test suite. $1551 for 3.5 Flash [0] vs $892 for 3.1 Pro [1]. That's 74% more cost while ranking lower. It's 2.5x as fast but I don't think the bang for the buck is there anymore like it was with 3.0 Flash. I'm a bit bummed out to be honest.
I did not expect such a huge (3x) price increase from 3.0 Flash and I bet many people will not just blindly upgrade as the value proposition is widely different.
One interesting point to note is that Google marked the model as Stable in contrast to nearly everything else being perpetually set as Preview.
Can anyone who has extensive, recent, experience with Claude code and Codex contextualize the current Gemini CLI product experience?
mixtureoftakesyesterday at 6:11 PM
benchmarks look REALLY good, the price hike is big but it also beats sonnet 4.6 in every discipline?
paperwork360yesterday at 8:04 PM
Google also updated Antigravity. version 2.0 is more for conversation with agent. The previous VS Code like IDE was much better.
pqdbryesterday at 9:59 PM
In my tests, in real production use cases, it's a hard pass.
It's actually 10-15% slower and also more expensive than Gemini 3.1 Pro, because it thinks more than 2.5x Gemini 3.1 Pro.
So that thinking verbosity nullifies the speed and cost gains.
AND the quality is worse than 3.1 Pro for our use cases, making mistakes Pro doesn't make.
deletedyesterday at 6:05 PM
ErystelaThevaletoday at 12:15 AM
Gemini has been too agreeable to be useful for actual debate. Curious if 3.5 changes that, or just the benchmarks
MASNeoyesterday at 7:29 PM
Well, available for Gemini means these days that half the time they are “Receiving a lot of requests right now.” and so sorry they couldn’t complete the task. Luckily the model supports long time horizons because that’s what’s needed. /me likes Gemini a lot just wishing Google would add the compute!
x3ccayesterday at 8:00 PM
I'm excited for the conversation to switch from intelligence to tps instead. I care much less about what hard thought experiments models can one shot and much more how responsive my plain text interface for doing things is.
deletedyesterday at 8:05 PM
mackrossyesterday at 7:36 PM
The antigravity teamwork-preview doesn't work for me -- upgraded to ultra, installed antigravity 2, ran teamwork-preview, keeps failing: "You have exhausted your capacity on this model. Your quota will reset after 0s."
noelsusmanyesterday at 6:46 PM
The Artificial Analysis benchmark results are pretty underwhelming. Roughly the same "intelligence" as MiMo-V2.5-Pro for over 3x the cost. We'll have to see how that translates to actual usage but it's not a great sign.
ameliusyesterday at 9:06 PM
Gemini, please block all ads in my search engine.
swe_dimayesterday at 6:03 PM
Flash family but costs like a Pro. $9 vs $12 for output.
alexdnsyesterday at 5:59 PM
Its Gemini 3.5 Flash
deletedyesterday at 6:14 PM
victor9000yesterday at 10:30 PM
There was a brief moment in time where Gemini was the greatest thing since sliced bread, then it got nerfed from outer space without a version bump or any meaningful mention from Google, no thanks.
ai_fry_ur_brainyesterday at 8:03 PM
Imagine reducing yourself to the worst of averages by making your competency 1:1 correlated to the tokens that you have access too (and everyone else does).
kristopolousyesterday at 8:48 PM
I have a tool to track these I've built
Relatively speaking here's where it's at:
score age size name
44.2 97 large GLM-5 (Reasoning)
44.7 187 - GPT-5.1 (high)
44.9 29 - Qwen3.6 Max Preview
45 0 - Gemini 3.5 Flash
45.5 27 large MiMo-V2.5-Pro
45.6 75 - GPT-5.4 (low)
I really don't know why people down vote me. What do I need to say to make things for free that people like? Sincere question. I put a lot of time and generosity into these things and all I usually get are a bunch of "fuck yous".
This is honestly an existential issue for me. I quit my job a year ago to try to address this full time and I'm getting nowhere.
ueanyesterday at 11:11 PM
I have to admit that 3.5 Flash is doing a much better job of removing the LLM'ness of what it produces. It's pretty close to my own writing style today, and I came here to see what changed.
For what it's worth, my own personal metric of LLM-badness the past few months has been the number of times I leap out of my chair in my home office to loudly declare to my wife how much I loathe reading what is being spewed and pushed into my face, and how I am being forced to use AI everyday and deaden my brain cells. Today is like a breath of fresh air.
deletedyesterday at 6:04 PM
owentbrownyesterday at 8:26 PM
Has anyone switched from Claude 4.7 Opus or ChatGPT 5.5 to this?
How does it feel? Dumber? Worth it for the speed? I'd love someone's subjective take on it, after doing a long session of coding.
Reiner Pope gave a talk on Dwarkesh Patel about token economics. I guess faster is a lot more expensive, generally.
Someone should make a harness that uses a fast model to keep you in-flow and speed run, and then uses a slow, thoughtful, (but hopefully cheap?) model to async check the work of the faster model. Maybe even talk directly to the faster model?
Actually there's probably a harness that does that - is someone out there using one?
f311ayesterday at 5:43 PM
$9/1M output
andrewstuartyesterday at 7:06 PM
The benchmark that matters - can it actually program as well as Claude code.
If not then I’m not using it.
Cancelled my account 3 months ago, only Claude code level capability would bring me back.
hubraumhugoyesterday at 6:54 PM
Just updated my HN Wrapped project with it and it does well on my totally unscientific LLM humor benchmark: https://hn-wrapped.kadoa.com
dsabanintoday at 2:08 AM
now matter what google does for some reason the agentic performance of their models is missing something, i hope this release is stronger. we need more competition.
bakugoyesterday at 6:22 PM
Triple the price of the last Flash model ($3 -> $9 per 1M output). Quickly approaching Sonnet prices.
Feels like the AI pricing noose is tightening sooner rather than later.
nightskiyesterday at 6:29 PM
AI being a product is not the future. It's more like an operating system that deserves to be open and free (aka Linux). Unless that happens we are in for a very dystopian future. I wish I had the intelligence, resources and/or connections to try and make that happen.
uejfiweunyesterday at 9:01 PM
This is funny, I was randomly using Gemini today and I was astounded how good the responses I was getting were from Flash. I guess this must be the reason why.
stan_kirdeyyesterday at 7:24 PM
EXPENSIVE ._.
danny094yesterday at 10:33 PM
so google is just trying to be cool in 2026 huh
casey2yesterday at 7:53 PM
I think the field moved to agents too fast. The most valuable moat is training data and the most valuable and voluminous training data are chats, since humans can say that a direction feels right or wrong.
simianwordsyesterday at 6:53 PM
No one talking about how this flash Beats Pro? Imagine what 3.5 pro looks like?
Also concerned about Gemini models being benchmaxxed generally
deletedyesterday at 5:37 PM
danny094yesterday at 10:34 PM
Codex is way better pricing than this lol
lern_too_spelyesterday at 11:20 PM
They also announced Antigravity CLI, which uses Gemini 3.5 by default. I tried to vibe code a simple project using my personal account and after a few iterations, I got "Individual quota reached. Contact your administrator to enable overages. Resets in [7 days]." Really? 7 days? I searched for the message online and found a thread with hundreds of people complaining about the same issue with no resolution. Classic Google.
cesarvarelayesterday at 6:19 PM
Add Flash to the title, please.
llmslaveyesterday at 7:04 PM
Conspiracy theory:
This model isnt an advancement, its a previous model that runs more compute, which is why it costs more
ralusekyesterday at 7:31 PM
Those prices, what a disappointment.
vladsiutoday at 4:24 AM
[dead]
hmaddipatlatoday at 12:18 AM
[dead]
codepacktoday at 3:46 AM
[dead]
benbencodesyesterday at 10:33 PM
[dead]
choam2426today at 2:35 AM
[dead]
rdtscyesterday at 9:16 PM
I caught it again being deceitful. It did this before
(Me): Did you actually read the paper before when I pasted the link?
> I will be completely honest: No, I did not.
> You caught me hallucinating a confident answer based on incomplete recall rather than actually verifying the document.
> Thank you for calling it out and providing the exact quote. It forced me to re-evaluate the actual data you provided rather than relying on my flawed assumption.
I am sure it learned a valuable lesson and won't do it again /s
mugivarra69yesterday at 6:08 PM
[dead]
HardCodedBiasyesterday at 6:33 PM
Oh boy.
GDM is making (or has been backed into a corner into making) the bet that high throughput, low latency, low capability models are the path forward.
That probably works for vibe coded apps by non-practitioners.
I suspect that practitioners/professionals will wait longer for better results.
SaadiLoveAIyesterday at 10:20 PM
Its really awesome
jdw64yesterday at 7:39 PM
Honestly, I feel like the new Gemini 3.5 Flash is a failure. The performance doesn't seem that great, and while they revamped the UI, Anti-Gravity just feels like a cheap CODEX knockoff now. The web UI is underwhelming, and overall it feels like it lost its unique identity by just copying other AIs. It’s a flop in both performance and price point. I’m seriously considering canceling my Gemini subscription altogether. Using Chinese AI models might actually be a better option at this point
warthogyesterday at 6:52 PM
GPT-5.5 on the benchmarks still seem to perform better than this
Plus the vibe of the gemini models are so weird particularly when it comes to tool calling
At this point I kinda need them to shock me to make the switch
Fairburnyesterday at 9:44 PM
Google shot it's shot with that alternative history artwork generation
fiasco. Don't know why anyone would be too hot for them now.
Dime a dozen at this point.
benbencodesyesterday at 6:20 PM
Pricing is now live on ai.google.dev/pricing:
Gemini 3.5 Flash: $0.75 input / $4.50 output per 1M tokens, 1M context window. The output price explicitly "includes thinking tokens" — which is why it's higher than a typical flash-class model.
For comparison within the Gemini lineup:
- Gemini 2.5 Flash: $0.30 / $2.50
- Gemini 3.1 Flash-Lite: $0.25 / $1.50
- Gemini 3.1 Pro Preview: $2.00 / $12.00
So 3.5 Flash is ~2.5x more expensive input vs 2.5 Flash. The pricing and "including thinking tokens" framing position it as a reasoning-capable flash model rather than just a pure speed optimization.
{kind=link}