I’ve always thought the US Postal Service is such a technological marvel. They somehow manage to identify and route billions of pieces of mail and I have to imagine their tech is significantly more primitive than this. Not only that but US addresses are absurdly non-standardized, you can often write the same address multiple ways and have it deliver to the same location. I’m sure there’s plenty of published knowledge in this area, but whenever I see announcements about OCR it feels like this should be a solved problem if it’s been accomplished at the scale of USPS for many years.
andrewmutztoday at 3:34 PM
A tangential observation: the video on the linked page wasn't what I expected. I thought Mistral was a european AI company, so I didnt expect the video to be filmed in San Francisco featuring three people who don't seem to be european.
I'm not against them being a global organization, that's wonderful. I was just surprised. I expected a parisian office and european accents.
bekleintoday at 6:04 PM
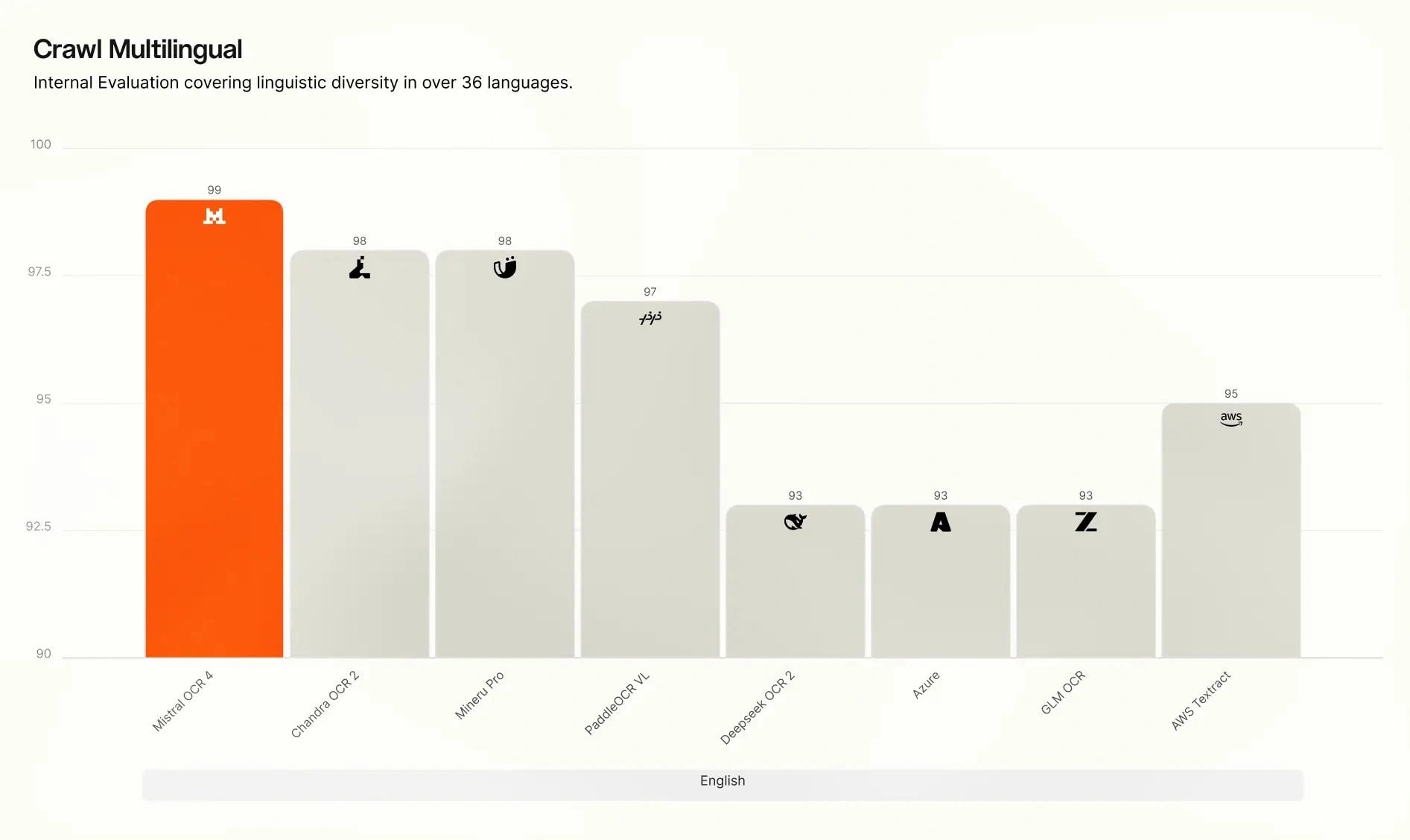
All AI labs really need to stop using truncated y-axes for benchmark bar charts...
It's cheap at $4/1k, but I'm hesitant to even benchmark this one again since the previous versions were all "98% accurate based on internal benchmarks of 4 pdfs" and ended up falling short of almost everything else on the market [1].
Even in this one, they just report that OlmOCRBench and OmniDocBench have "known limitations" and that's why they report flagship numbers from their internal benchmark.
Tested with Malayalam, normal handwriting got accurate but a slight different style got detected as kannada. Have samples if required, which sarvam got done with 99% accuracy leaving one text error.
nickvectoday at 6:27 PM
Naive question: is Claude no good at OCR? Was surprised to see that none of Anthropic's models were included in the benchmark comparisons.
mcbetztoday at 3:23 PM
Little on differences other than bounding boxes and double the price compared to their previous OCR v3 model from December - https://mistral.ai/news/mistral-ocr-3/ - other benchmarks were used back then.
utopiahtoday at 3:04 PM
"A note on out-of-scope use. OCR 4 is a document-understanding model, not a decision-maker. It is not intended for medical diagnosis, legal advice or judgment, high-stakes financial decisions, safety-critical systems, real-time/latency-sensitive processing, or non-document inputs (raw audio, video, etc.). "
Can't wait for the "oh so innovative" manager who will suggest during the next meeting "Ok... but what if WE used it for high-stakes financial decisions on non-document inputs like a photo from my phone?"
I guarantee you somebody on HN is going to comment about this "idea" next week.
bastawhiztoday at 4:36 PM
The comparisons rank it against GPT and Gemini but not Claude. Is Claude's vision support simply not competitive when it comes to OCR tasks?
Insanitytoday at 3:14 PM
Recently I tied OCR with Opus 4.8. (I know, not technically right tool for the job). All I needed to do was extract dates from receipts. It got about 20% of the dates wrong yet rated all as “high confidence”.
Should have probably tried a more OCR specific model
trilogictoday at 6:08 PM
Mistral keeps reminding us that doesn´t just brew great coffee they can build great AI too.
Hats off to the team.
Mistral O.C.R. (Only Cool Results)
Duckitoday at 2:42 PM
I was processing 55 year old paper files, most of them severely degraded, with its predecessor model. I was very impressed! I also tried Abbyy Finereader but it didn't even come close in my experience.
MostlyStabletoday at 3:24 PM
Does anyone know of OCR benchmarks that include hand-written documents? I'm currently using Gemini pro 3 for this, and error rates are quite good, but it's a little bit pricey, and I'd be interested in a cheaper model that could perform as well, but almost all the OCR benchmarks I'm aware of (and I believe all the ones included in this announcement) are about printed/typeset text.
pmxitoday at 3:19 PM
This has been a niche where Mistral has actually been successful. Btw, Hindi and Japanese are bucketed in "Rare Languages," which is odd.
stri8tedtoday at 3:15 PM
Way too expensive. Google vision OCR (which they failed to compare against), is $1.50 per 1k pages. Vs $4 from Mistral.
JGB100today at 5:37 PM
Not well tested. It switched all U.S. (") double quotation marks to UK-style (') single quotation marks, ignoring the source document. Useless in the US.
coulixtoday at 4:25 PM
I wonder how it does compare to reducto, pulse, extendai.
Ninjinkatoday at 4:37 PM
Is there a complete list of the languages they support, and benchmarks by language, instead of just "Rare Languages"?
Are there benchmarks for how this performs on charts, or maybe more accurately, plots? I've yet to find a model that can digitize a plot into X,Y points with some accuracy in my use case of digitizing old datasheets.
jppopetoday at 2:44 PM
Is there something wrong with their certificate? Chromium is saying https isn't valid
ge96today at 2:57 PM
1000 pages for $4? damn how does it compare to llama parse I wonder
sscaryterrytoday at 5:40 PM
Why the chart crimes?!
gpmtoday at 3:12 PM
Do these models (this one or its competitors) do handwriting recognition?
v3ss0ntoday at 4:35 PM
Not opensource right?
dominotwtoday at 4:51 PM
starting y axis from 50 and 95 is a bit mileading
vasylvdtoday at 6:37 PM
[flagged]
greenleafone7today at 3:22 PM
After paying for Mistral and using it for a while I genuinely hated it. It's a productivity black hole and can't realistically compete with anyone. I chose it only because it was European, but no. I'd rather let my one year subscription go to waste than use anything 'Mistral'.
{kind=link}